

In my previous primer on Elo ratings, I talked about different ways of calculating Elo ratings with a view of measuring form and/or class. This primer will look in a bit more depth at how I arrived at the specific numbers for the variables.
The main variables in an Elo model are:
- Starting ratings (discrete versus continuous)
- If continuous, then the reversion to mean discount of ratings
- Calculation method (margin vs result/WTA)
- K, weighting for each game
- h, homefield advantage
- p, margin factor
Some are derived from game data, others from optimisation. Let’s tackle them one by one.
Starting ratings & reversion to mean discount
The difference between a continuous rating model or a discrete one is aesthetic. From a prediction point of view, continuous does better because you don’t waste as much of the early rounds trying to work out who’s who in the zoo. Discrete gives everyone the same starting point (1500) so it makes season to season comparisons of top-rated teams more straightforward but takes a few rounds for each team to be rated properly.
Excluding Eratosthenes, the reversion to mean discounts were chosen for maximum prediction power. I think it’s interesting that it’s not 100% or 0% which implies that the reversion to mean is a real variable. The margin discount of 80% is massive (meaning a 1600 team becomes a 1520 team at the start of the next season) compared to 538.com’s NFL discount of 33% and The Arc’s AFL discount of 10%. The 50% for result/WTA models if a bit more reasonable. Other than NRL’s inherent lack of predictability, I don’t know what to attribute this difference to.
Calculation method
Choosing between margin and WTA is a somewhat aesthetic choice. Again, margin predicts slightly better than WTA (about 1% better) but WTA is a bit more intuitive. The difference is in the (W-We) of the re-rating. Recall that the formula is:
Rn = Ro + K*(W-We)
In WTA, W is 1 for a win, 0 for a loss or 0.5 for a draw. In margin, W is calculated as follows:
W = 1 / (1 + e^(-p * margin) )
(Yes, the formula looks shit. It’s WordPress, leave me alone)
So the W for margin calculations depends on the margin at full time, hence the name. Let’s work through a short example. In round 14 of the 2011 season, Melbourne hosted Sydney. Applying the home field advantage, Melbourne was sitting on 1570 and Sydney on 1430, a gap of 140 points. This meant the Storm were favourites with a 69% chance of victory. The Storm were victorious to the tune of 17 points. Using our formula above and a value of p = 0.0601, the W was calculated to be 74%. Substituting these into the re-rating formula:
Rn = 1547 + 105*(0.74 – 0.69)
Rn = 1552
The Storm exceeded expectations (74% worth of margin compared to a 69% expectation) and so their rating went up. Considering that it was a solid win over a middling opponent, the rating did not increase by much. However, had the margin been less than 13.3 points (roughly equal to the 69% expectation), the Roosters’ rating would have risen and the Storm’s decreased.
Value of K
These are the K values that I’ve used:
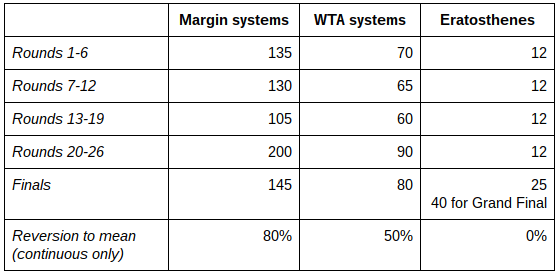
K values are important because they decide how fast the ratings move in response to individual results. If you did physics in school, it’s like the mass on the end of spring – the heavier the mass, the bigger the oscillations in the spring.
The margin models K values are very high. The Arc generally uses between 62 and 82 and 538.com’s NFL Elo ratings use 20. The high ratings are partly so that the system can respond quickly to changes in form but also because the (W-We) part is generally quite small. In the example above, the difference is only 5%. The K values are halved in the WTA models because the (W-We) difference is usually bigger. For example, in the game above, the Storm’s win would have worked out to (1-0.69) = 0.31 instead of 0.05 – a larger move in response to a single result, so the K values are lower so as to not overshoot. The K values in these models are optimised for result prediction. I spent a lot of time looking at hundredths of a percentage improvement in prediction rates so trust me on this.
Eratosthenes is different in that the K values are selected so that a team’s Elo rating roughly reflects their three year winning percentage, so it moves quite slowly. I’ve mentioned this before but are you wondering how an Elo rating converts to a winning percentage? No, well, you’re going to find out anyway.
Tangent: Converting margins to ratings and vice versa
The idea comes from the fact that over a long enough period, the average rating of a team’s opponents is about 1500. Elo ratings are zero-sum, so if every team starts on 1500 and every change in ratings deducts the same amount from one team that is added to another’s, then the average rating will always be 1500 (or close enough). A team also generally plays as many home as away games so the home field advantage is nullified.
So if we can put a percentage odds against a team of particular rating against a 1500 team, then that will tell us what their win percentage would be over the long run if they maintain that rating. I’ve done the maths to convert between the two – here you go:


A 100% win rate introduces a divide by zero, so I’ve rounded down to 99.9%. Fortunately, no one in the NRL’s nineteen year history has gone 24-0 and may it never happen because it would really mess up my numbers. Incidentally, the lighter orange table can be inverted if your team is below 1500 by taking the corresponding level above. E.g. if you have a 1490 team, it’s win percentage is 48.6%, the opposite of the 1510 team.
The zero sum aspect poses a unique challenge for Eratosthenes. The series starts in 1998 with the formation of the NRL. In that time, we’ve lost a few clubs and gained the Titans. When clubs fold or merge, they usually aren’t on a 1500 rating so their exit leaves the average unbalanced. I dealt with this in two ways:
- Mergers – Wests & Balmain, St George & Illawarra and Manly & Norths were all below 1500 at the time of their merger. The new entity’s rating has the total difference between the old clubs’ ratings and 1500 subtracted from it, e.g. if the two teams are 1460 and 1490, the merged team is 1450.
- Folding – Adelaide and Gold Coast folded after 1998. I took their missing points, pooled them, divided by three and then deducted them from the returning Rabbitohs in 2002, the de-merged Sea Eagles in 2003 and the Warriors in 2001 (who were previously Auckland) because dealing with these discontinuities was a pain in the ass.
No, the penalty is not applied to salary cap breaching teams and yes, I realise this is grossly unfair. If you think of a good way to quantify the rating point deduction for breaches, let me know.
Homefield Advantage
Once you realise that there’s a relationship between win percentages and ratings, then the homefield advantage is easy to work out. You look at how often the home team wins, which is 56.9% at full time over the 3803 games from 1998 to 2016, convert that to a rating, which is worth 48.3 bonus points, and add half that to the home team and deduct the other half from the away team. The model’s use the home winning rate from the previous five years, so it has been trending slowly down. In 2016, the home win rate was only 53.2%. In 2017, the rating advantage is only 32 points.
I also investigated whether different home field advantages should apply for different clubs but the small sample size (e.g. the 620-odd home games for Queensland teams over 19 years) is overwhelmed by the difference in quality of clubs. Brisbane and Melbourne play much better at home because they were much better teams than Adelaide or either of the Gold Coast teams. Is that home field advantage or underlying class of the club? Interestingly, the rate of home wins for Queensland teams is 55.9%, a rate dragged down by the early Cowboys and the ongoing uselessness of the Titans. It’s a small difference that doesn’t seem to merit much more consideration unless I make an assessment based on the specific clubs involved and their history – maybe a future experiment.
Margin Factor
This controls the relationship between an expected result and the actual scoreline. When we take two team’s ratings, we can calculate an estimate of their probability of winning the match (e.g. a 1550 team against a 1500 team should be in the ball park of 56% chance of a win). But when the game is over, we don’t get a percentage, we have a margin on the scoreboard, which has to be converted back to a percentage to re-rate the teams. The factor in this conversion, p, is based on historical data of the difference in average scorelines home and away teams over the previous five seasons. Typically, this is about four points, give or take, and so we use a re-arranged version of the formula for W under the margin systems to find p varies from 0.08 to 0.05, depending on what the previous seasons were like. Using five years of data and the difference of the average scorelines seems to yield the best predictions. I’ve tried using double and half the values, shorter and longer timeframes and the average of the margin (different to the difference between the average home and away scores) and none seemed to work as well.
This primer has been three times longer than I wanted these to be but it should give you a detailed insight into the underlying mechanics and limitations of these models.
